Curriculum Learning for Knowledge Distillation in LMs
Abstract
Knowledge distillation (KD) is a powerful, well-established model compression technique that can face performance limitations when the capacity difference between student and teacher models is severely mismatched (Cho and Hariharan, 2019), or when multiple teachers cause competing distillation objectives (Du et al., 2020). To address these issues and improve performance in KD for large language modeling, I explore the implementation of two ideas: using curriculum learning during KD, where training data is sorted based on difficulty, and using Selective Reliance during KD, where a student language model selectively leverages teacher distillation loss for data samples deemed difficult by the curriculum. See the full report here.
Introduction
Knowledge Distillation (Hinton et al., 2015) is a model compression technique commonly deployed in settings where large models are difficult to store and run. Vanilla KD comprises of a dual model student-teacher modeling framework, where a small capacity student model aims to mimic the performance of a larger capacity teacher model by learning the distribution of the output labels generated from the teacher model trained on the same dataset. Specifically, the student model uses a bipartite loss function L_student that incorporates both L_kd (the KD loss measured by the KL divergence between the softmax of the student output logits PS and the softmax of the teacher output logits P_T , scaled by the temperature parameter τ ) and L_ce (the standard cross entropy training loss using the true labels ytrue). The parameter λ controls the weight given to each component loss. The student loss and its component losses are defined below:
$$ L_{ce} = CE(y_{true},P_S) $$ $$ L_{kd} = \tau^2 KL(P_T,P_S) $$ $$ L_{student} = (1 - \lambda)L_{ce} + \lambda L_{kd} $$
The general framework is visualized below:
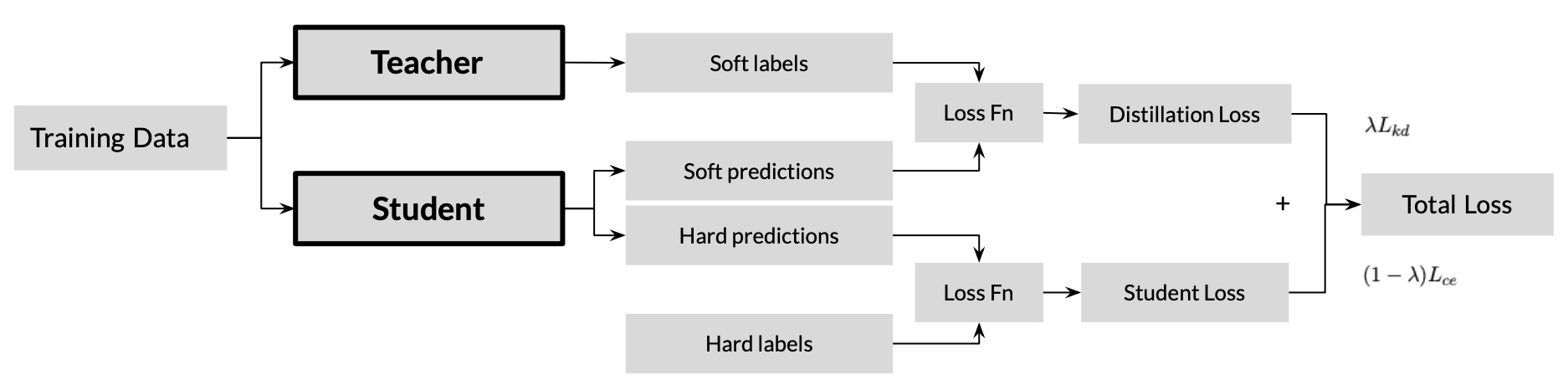
However, KD has been shown to provide minimal to no performance gains for certain tasks, such as image recognition on ImageNet (Zagoruyko and Komodakis, 2016). Cho and Hariharan note that empirical results establishing the generality of KD efficacy for various tasks are nonexistent. They examine the reasons behind these failures, noting that large differences in student teacher model capacities may limit the student model’s ability to minimize both training loss and KD loss, forcing the student to minimize the KD loss over the train loss. In addition to capacity gaps between student and teachers, KD frameworks that involve distillation from an ensemble of teachers require n-paritite loss functions, in which conflict can exists between different teacher models, which can adversely effect distillation loss (Du et al., 2020).
From these findings, I propose selective reliance, a KD technique for dynamically changing the student’s reliance on KD loss, in order to improve model accuracy. Selective reliance is implemented by updating λ in LStudent at the sample level, where λ is determined by the difficulty of the sample. Difficulty is defined in the context of Curriculum Learning (CL), a training strategy for improving model convergence speed and accuracy that involves training on easily learnable samples before more difficult ones (Bengio et al., 2009).
Difficulty rankings for samples can be determined using the confidence scores generated by either the teacher model (teacher-generated curriculum) or the student model (student-generated curriculum). In the former, the teacher model would also act as the difficulty scoring function (Hacohen and Weinshall, 2019) for each datapoint in the the student’s curriculum, calculated before the student training process. In the latter, the student model would generate its own curriculum during student training by looking at confidence scores generated during previous epochs in training, as described by snapshot learning (Zhao et al., 2021). For this experiment, I use the confidence scores generated by the student model (student-generated curriculum) during training. I hypothesize that relying on the teacher model is only in the student’s best interest when the sample being evaluated is “difficult” as determined by the curriculum, and that accuracy yielded from vanilla knowledge distillation (KD) and knowledge distillation with curriculum learning (KD-CL) can be improved upon with selective reliance (KD-CL-SR) techniques built into the distillation framework.
See the full report here.